Плагин Document
| Плагин предназначен для генерации и учёта печатных форм документов. Понятие "документ" здесь трактуется достаточно широко: так это может быть и HTML отчёт, генерируемый из очереди процессов. |
Механизм работы
Схематично принцип работы плагина изображён ниже. Синим цветом выделены блоки с использованием устаревшей XSLT технологии. Она поддержана в режиме обратной совместимости.
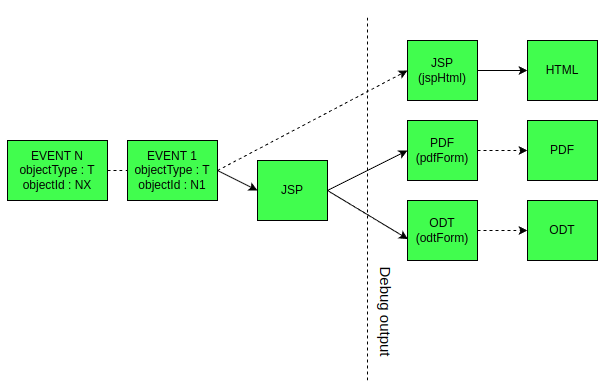
Однако все XSLT шаблоны рекомендуется в ближайшем будущем заменить на JSP.
Причины, по которой технология шаблонов была заменена:
-
унификация, JSP уже массово используется в системе;
-
производительность и ресурсоёмкость у JSP шаблонов существенно ниже;
-
затруднённый доступ к Java API из XSLT, фактически необходимость создания каждый раз XML оболочек для существующих Java методов.
Пояснения по схеме выше. Изначально на вход шаблонизатора подаётся одно либо набор событий с идентификаторами объектов, для которых следует сгенерироват документ и требуемом шаблоне. Идентификатор объекта - это код контрагента, процесса и т.п. Одно событие - генерация документа непосредственно для объекта, блок событий - генерация, например, из очереди процессов.
Есть некоторая разница в генерации событий в зависимости от результирующего формата. При генерации HTML документа из многих объектов генерируется одно событие, т.к. HTML подразумевает единый корень документа. При генерации PDF генерируются несколько событий и результаты склеиваются. Генерация ODT/DOCX и прочих форматов для нескольких объектов невозможна. (*для docx и xlsx форматов генерация для нескольких объектов реализована)
| При использовании устаревшей XSLT (type=xsltHtml) генерации HTML фрагменты с результатами для отдельных объектов также склеиваются. В результате получить целостное HTML дерево с его помощью невозможно. Однако, большинство современных браузеров всё-таки отображают такой результат корректно. |
С системой поставляется набор примеров генерации различных видов документов. Примеры JSP файлов с инструкциями по их настройке в комментариях расположены в каталоге webapps/WEB-INF/jspf/user/plugin/document /template/example
Генерация документа
| Это описание способа генерирования документов с использованием билдеров и контекстных переменных с описанием методов получения каждого поля. |
Для генерирования документа используется ContentBaseDocumentGenerator либо DocumentGenerator. Если вы хотите использовать этот способ генерации, в конфигурации паттерна документа в параметре выбора скрипта необходимо указать:
document:pattern.N.script=ru.bgcrm.plugin.document.docgen.ContentBaseDocumentGenerator| Подробнее о том, как создать свой билдер и дополнять методы для получения данных описано в документации к Билдерам полей. |
| Документация по DocumentGenerator. |
Описание работы
Генератор использует подход, при котором описываются данные для записи в документ, т.е. единицей является информация, заполняемая в, заранее подготовленные, интерактивные поля документа.
Шаги работы:
-
Из шаблона, указанного в конфиге, берется список интерактивных полей для заполнения. Получение происходит через метод интерфейса ru.bgcrm.plugin.document.docgen.DocBuilder#getFieldNames
-
По имени поля сначала ищется соответствующая контекстная переменная, причём происходит комбинированный поиск. Так, для сущности процесса ("process"), происходит поиск не только по собственным переменным, но и по переменным первой найденной связанной сущности единого договора ("bgbilling-commonContract"), а также первой найденной сущности контрагента ("customer"). Похожая логика работает в отношении единого договора - к его контекстным переменным добавляются переменные контрагента.
-
Если для данного поля находится подходящая контекстная переменная, её значение записывается в Map - отношение имени поля, к его значению.
-
Иначе по имени поля, определяется метод билдера, который вызывается, для получения значения поля
-
Данный метод вызывается, а полученное значение преобразовывается в String
-
Значение записываются в Map - отношение имени поля, к его значению.
-
По полученному отношению заполняется шаблон документа. Для заполнения испльзуется интерфейс DocBuilder#writeValues, который имеет имплементации для DOCX и PDF.
-
Сгенерированный документ записывается в объект DocumentGenerateEvent в виде байтов.
Билдеры полей
Билдер полей представляет из себя класс содержащий методы получения данных конкретного поля. Как правило класс насле́дуется от класса FieldDataBuilder в котором есть общие методы по работе с получением данных для докуметов. Новый класс билдера следует помещать в пакет ru.bgcrm.dyn.ufanet.document.builder.
Создание билдера:
-
Создать класс в пакете ru.bgcrm.dyn.ufanet.document.builder
-
Наследовать от FieldDataBuilder
-
Добавить новый класс в конфигурацию "Плагин Document" в параметр handler.{@inc:id}={class path}
public class TmcFieldsBuilder extends FieldDataBuilder
{}Объект билдер создается тогда, когда требуется получить значение поле у одного из его методов, описанных с помощью аннотации @FieldName("field_name"). За создание объекта билдера отвечает класс DocMapper. Какой конкретно объект билдера нужно создать определяется по имени очередного поля - по нему получается Class объекта из DocHandlersRegister.getBuilderMethod("field_name").
| После создания, объект кешируется в DocMapper до конца генерации всего документа. При генерации следующего документа, билдер будет создан заново. |
При создании, билдеру поступает контекст. Контекст состоит из DocumentGenerateEvent и Connection.
В методе билдера можно использовать данный контекст, уже некоторые определенные DAO и методы (например получения родительского процесса) из суперкласса.
Вызовы методов билдера
Когда вам необходимо добавить обработчик для поля, которого еще нет, вы можете либо добавить его в уже существующий класс билдера, или, если вы можете выделить группу полей в отдельный класс, создать новый билдер.
Создание метода обработчика
Пример метода:
@FieldName("serv_city")
public String getCity(){
return getAddress()
.map(this::extractCity)
.orElse(null);
}Метод для получения значения по имени поля строится по следующим правилам:
-
метод должен быть помечен аннотацией FieldName;
-
метод не имеет входных параметров.
Возвращаемые значения
Метод может возвращать любые значения. Не обязательно (даже не рекомендуется) приводить их к String самостоятельно. Например для методов возвращающих стоимость (чье лучшее представление BigDecimal) или состояния чекбокса (представленное boolean). Полученные значения приводятся к String с помощью FieldDataMapper.getValue. С актуальным списком классов для преобразования лучше ознакамливаться в данном методе.
| Методы билдеров должны заботиться лишь о данных, а не об их представлении. |
Возвращаемые коллекции
Метод может возвращать любого наследника Collection. Это может быть полезно при:
-
Заполнении таблиц. Имена полей в таблицах (списках) формируются с индексами через нижнее подчеркивание (field_1, field_2). В таком случае в качестве названия поля следует использовать имя поля без индекса (field) и возвращать коллекцию.
Пример:
@FieldName("monthly_price")
public List<RentCost> monthlyPrices() throws BGException {
List<StorageLeftoverMoving> tmcList = getSpecTmc();
return defineRentCosts(tmcList);
}В данном примере возвращается список арендных плат для полей "monthly_price_n", где n индекс поля.
-
когда поле может состоять из нескольких составляющих и они все объединяются в одно поле.
Пример:
@FieldName(value = "fio_si", fillingMode = SINGLE_FIELD)
public Set<String> companyRepresentatives() throws BGException {
Process parentProcess = getParentProcess();
return getProcessExecutors(parentProcess).stream()
.map(this::getUserTitle)
.collect(Collectors.toSet());
}Код выше возвращает список представителей компании или СИ, которых может быть несколько, но они все должны заполняться в одно поле. Для подобного поведения используется дополнительный параметр аннотации @FieldName - fillingMode. По умолчанию это значение равно TABLE - что предполагает, что данные будут заполняться в листовые поля с индексами как в примере выше. Так же в аннотации есть параметр delimiter, который определяет разделитель для списка полученных данных. По умолчанию это ", ".
Передача дополнительных данных в билдер
На данный момент единственный способ передать данные внутрь билдера - через DynActionForm. Необходимо иметь в виду что такой способ является достаточно накладным, так как необходимо преобразовывать данные в текстовый формат. Однако если запрос на генерацию приходит из вне, например через API работы с ЭДО ('EDOProcessAction, EDOAgreementAction'), и эти данные уже в форме, то можно их сразу получить в виде класса через методы 'parseBody' или 'parseBodyFromParam'.
Важное замечание по работе с ЭДО
При текущей модели электронных документов, они оборачиваются в процесс "Документ", обработчик которого вызывает генерацию документа. Из этого следует, что при создании метода билдера поля необходимо учитывать, что при получении данных из процесса они находятся не в текущем, а в родительском процессе. (Получить его можно через метод FieldDataBuilder#getParentProcess())
Конфигурация
Для добавления генератора документа в конфигурации указывается запись вида:
document:pattern.<id>.title=<title>
document:pattern.<id>.scope=<scope>
# заменой этого класса своим возможно полностью переопределить логику генерации
документов
document:pattern.<id>.script=ru.bgcrm.plugin.document.docgen.
CommonDocumentGenerator
document:pattern.<id>.type=<type>
document:pattern.<id>.jsp=<jsp>
#
# необязательные параметры общие
document:pattern.<id>.result=<result>
#
# если результат не stream только - то имя сохраняемого документа
document:pattern.<id>.documentTitle=<doc_title>
document:pattern.<id>.titleRegexp=<title_pattern>
document:pattern.<id>.additionalParametersJsp=<additional_params_jsp>
#
# необязательный параметры для type=pdfForm/docxForm/odtForm
document:pattern.<id>.file=<file>
document:pattern.<id>.flattening=<flattening>
#
# устаревший параметр
document:pattern.<id>.xslt=<xslt>Где:
-
<id> - уникальный числовой идентификатор типа документа;
-
<title> - отображаемое наименование шаблона, необходимо только для шаблонов, которые можно выбрать;
-
<scope> - тип сущности, для которой генерируется документ, см. далее;
-
<type> - тип генерируемого документа, описание типом см. далее;
-
<jsp> - путь к JSP шаблону, генерирующему HTML, либо подготавливающему данные для шаблонов;
-
<result> - допустимые значения через запятую: stream - не сохранять сгенерированный документ и сразу выдать его клиенту, save - сохранить документ;
-
<doc_title> - имя создаваемого документа;
-
<file> - имя файла со шаблоном документа (PDF форма либо иной исходный документ для подстановки параметров) рекомендуется располагать в каталоге ERP/docpattern;
-
<title_pattern> - REGEXP шаблон имени сущности, для которой будет предлагаться к генерации данный тип документа;
-
<additional_params_jsp> - JSP файл с дополнительными параметрами для генерации документа;
-
<file> - исходный документ, заполняемый данными;
-
<flattening> - 1, для типа pdfForm, если сгенерированный PDF документ следует сделать нередактируемым.
Возможные значения параметра , для генерации документов объектов ядра:
-
processQueue - шаблон используется для генерации печатной формы в очереди процессов;
-
process - шаблон для генерации печатной формы процесса, дополнительно вкладка "Документы" должна быть включена в конфигурации типа процесса следующим образом:
document:processShowDocuments=1
document:processCreateDocumentsAllowedTemplates=<коды шаблонов документов, доступных для генерации через запятую>Также интеграцию с Document поддерживают следующие плагины, для них возможны свои значения параметра <scope>:
Поддерживаемые типы (параметр <type>):
-
pdfForm - PDF форма, исходная форма получается из параметра <file>, поля формы заполняются из XML документа с параметрами, подготовленного с помощью JSP шаблона <jsp>;
-
docxForm либо odtForm - .docx либо .odt файл с макросами вида ${ macros }, значения которых заменяются значениями из XML документа с параметрами, подготовленного с помощью JSP шаблона <jsp>;
-
xlsxForm - .xlsx файл с макросами вида ${ macros }, значения которых заменяются значениями из объекта. Используется только со скриптом ru.bgcrm.plugin.document.docgen.ContentBaseDocumentGenerator. Реализовано заполнение таблиц, размер которых меняется в зависимости от содержимого: для этого необходимо макросами определить первую строку в шаблоне, необходимое количество строк таблицы будет добавлено в зависимости от содержимого.
-
jspHtml - преобразование исходных данных в HTML с помощью JSP шаблона <jsp>;
-
xsltHtml - (устарело) преобразование исходных XML данных в HTML документ с помощью XSLT шаблона <xslt>.
-
docxPictures - расширение типа docxForm, кроме обработки стандартных макросов ${ macros }, выполняется обработка макросов вида ${ pic:macros }* в описаниях изображений. Изображения с таким макросом в описании могут быть заменены на другой либо удаленыN
| PDF формы можно подготовить с помощью Adobe Acrobat, Master PDF Editor или аналогичной программы |
При использовании типов docxForm либо odtForm производится замена в текстовых файлах word/document.xml и content.xml макросов на значения.
Файлы эти расположены внутри архивов, коими по сути являются файлы этих двух форматов. Для проверки корректности макросов можно переименовать .docx либо .odt файл в .zip, открыть архиватором и просмотреть указанные ранее файлы. Важно проконтролировать, чтобы макросы шли сплошными блоками и находились поиском в текстовом редакторе. Возможны, например, такие варианты форматирования, макрос в этом случае корректно заменён не будет:
<text:span text:style-name="T2">${cardNumber</text:span><text:span text:style-name="T3">}</text:span>В этом случае макрос следует забить повторно и пересохранить документ, добившись примерно такого варианта:
<text:span text:style-name="T2">${cardNumber}</text:span>Пример настройки генерации HTML документа из карточки процесса (взят из примеров webapps/WEB-INF/jspf/user/plugin/document/template/example).
document:pattern.101.title=Пример процесс HTML
document:pattern.101.scope=process
document:pattern.101.script=ru.bgcrm.plugin.document.docgen.CommonDocumentGenerator
document:pattern.101.type=jspHtml
document:pattern.101.jsp=/WEB-INF/jspf/user/plugin/document/template/example
/process_html.jsp
document:pattern.101.documentTitle=document.html
document:pattern.101.result=stream,saveПри использовании не HTML результирующего формата вывод JSP шаблона используется только в режиме отладки (см. далее). Для заполнения полей в JSP шаблон передаётся объект field, методом set которого можно установить значения именованных параметров.
Установленные промежуточные данные возможно просмотреть в режиме отладки. Режим отладки запускается при генерации документа с зажатой клавишей Alt в режиме без сохранения на диск. Отладка выводится в отдельном окне.
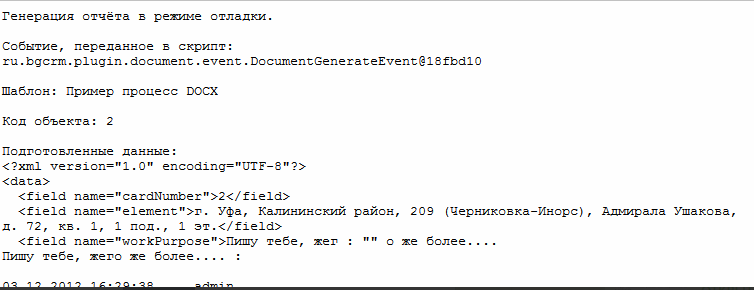
Режим отладки имеет смысл для типов шаблонов, где результирующим документом выступает не HTML. Он предоставляет возможность изучить вывод JSP шаблона с отладочной информацией и подготовленные им поля. Для шаблонов, генерирующих HTML отладка возможна сразу в результирующий документ. Плагин документов может быть использован для генерации отчётов в очереди процессов. Для запуска режима отладки в этом случае клавиша Alt должна быть зажата в момент выбора пункта обработчика в меню Ещё.
Интерфейс пользователя
В интерфейсе пользователя функционал плагина доступен на вкладках Документы различных сущностей. В таблице отображаются привязанные к объекту документы. Возможно удаление ранее привязанных документов, их открытие
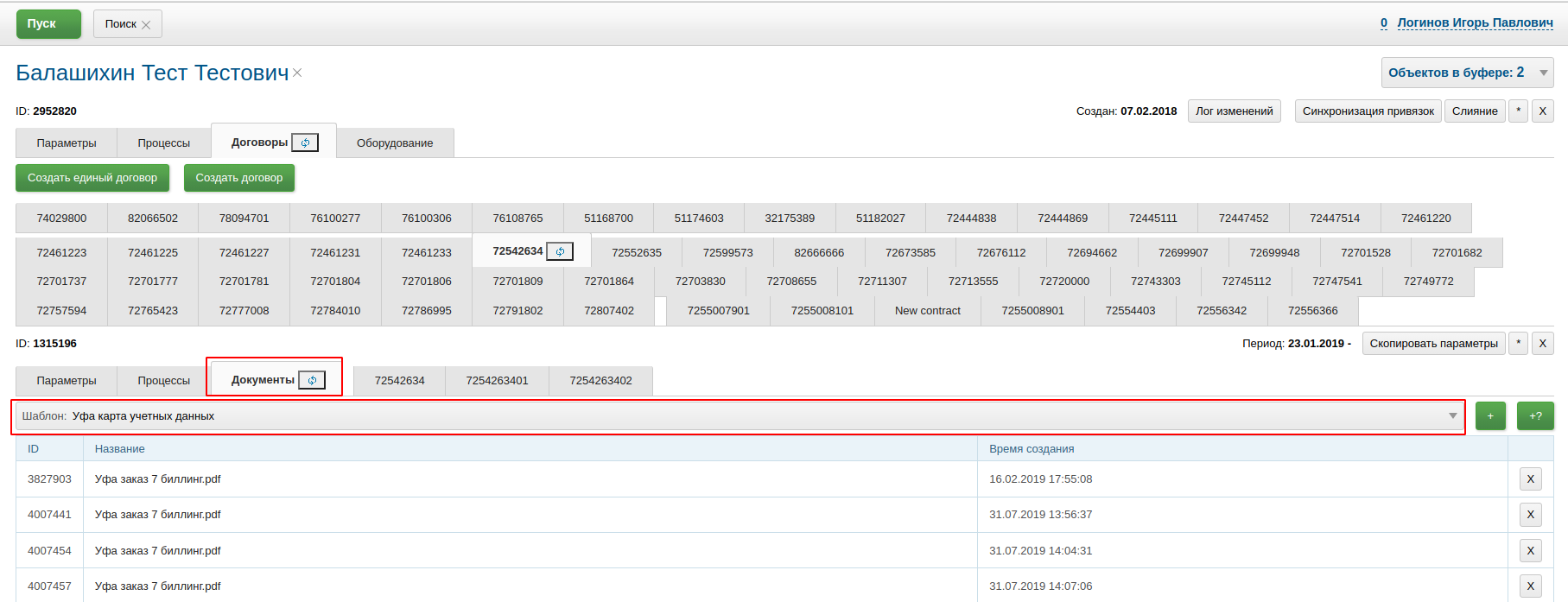
В выпадающем списке выводятся настроенные для данного типа сущности шаблоны документов. Далее кнопки генерации документа с сохранением и без (настраиваются с помощью result параметра в конфигурации шаблона). Кнопка +? позволяет загружать произвольные файлы.
При удержании нажатой клавиши Alt в момент генерации документа без сохранения запускается режим отладки.